1. Modelos de Ecuaciones Estructurales (SEM)
Introducción a los Modelos de Ecuaciones Estructurales
Los Modelos de Ecuaciones Estructurales (SEM) son una familia de modelos estadísticos multivariantes que representan la culminación de las técnicas que hemos estudiado, permitiendo estimar y testear complejas redes de relaciones entre múltiples variables.
- Nacieron de la necesidad de superar las limitaciones de los modelos de regresión tradicionales.
- Su principal ventaja es la flexibilidad: son menos restrictivos al permitir modelar explícitamente el error de medición, tanto en las variables que actúan como predictoras como en las que son predichas.
En resumen, los SEM nos permiten testear teorías sociológicas completas, que involucran tanto la medición de conceptos abstractos como las relaciones causales entre ellos.
La Lógica Confirmatoria de los SEM
- Guiados por la Teoría: Los SEM son fundamentalmente modelos confirmatorios. El investigador debe proponer, a priori, un modelo que especifique el tipo y la dirección de todas las relaciones de interés, basándose en un sólido marco teórico o en evidencia empírica previa.
- Objetivo Principal: El interés no es explorar, sino “confirmar” si la estructura de relaciones hipotetizada es consistente con los datos observados en una muestra.
- Base Empírica: La estimación del modelo se basa en analizar la matriz de varianzas y covarianzas (o de correlaciones) de las variables observadas. El modelo se considera bueno si la matriz de covarianzas que implica nuestro modelo teórico es muy similar a la que observamos en nuestros datos.
Ejemplo de Aplicación en Salud
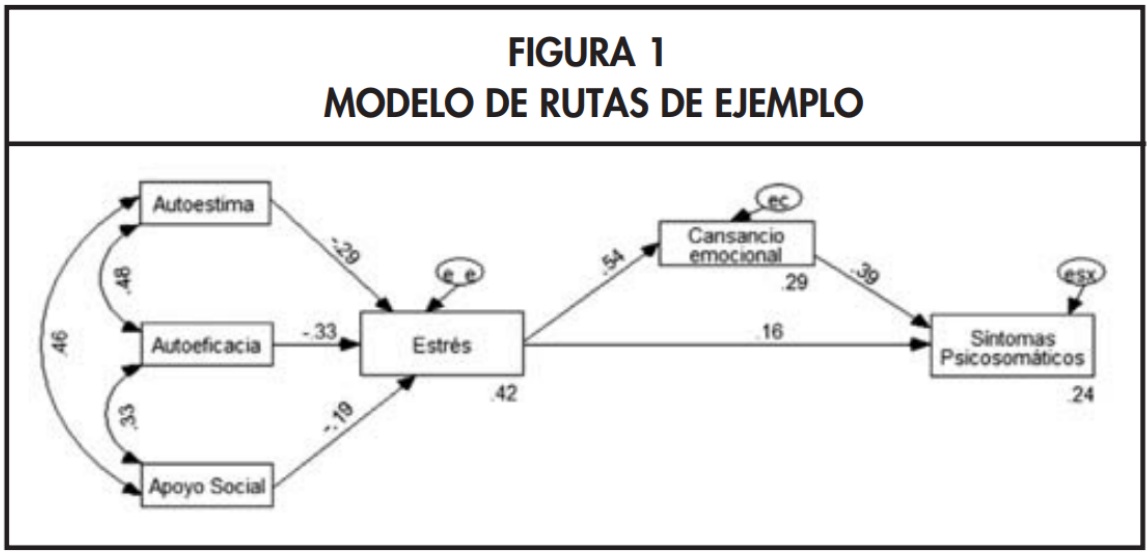
Imaginemos un modelo que busca explicar los síntomas psicosomáticos.
- Teoría: Se postula que antecedentes personales como la autoestima, la autoeficacia y el apoyo social influyen en los síntomas, pero no solo directamente, sino también a través de variables mediadoras como el estrés y el cansancio emocional.
- Análisis con SEM: La interpretación de los parámetros estimados (los “paths” o senderos) nos permite constatar estas relaciones. Por ejemplo, podríamos evaluar si el apoyo social tiene un efecto negativo sobre el estrés (reduciéndolo) y si, a su vez, el estrés tiene un efecto positivo sobre los síntomas psicosomáticos. El modelo nos permitiría cuantificar tanto los efectos directos como los indirectos.
![]()
SEM y Causalidad: Una Advertencia Crucial
1. Estimación Estadística NO es Prueba Causal:
- Aunque los diagramas SEM utilizan flechas que representan una hipótesis de influencia causal, la estimación de un parámetro significativo NO demuestra por sí sola la existencia de causalidad.
- SEM es una técnica que evalúa la consistencia de los datos con un modelo causal propuesto. Un buen ajuste del modelo significa que la teoría no es refutada por los datos, pero no que es la única explicación posible.
- La defensa de la causalidad requiere, además del ajuste estadístico, un sólido argumento teórico y, preferiblemente, un diseño de investigación que permita inferencia causal (ej. datos longitudinales, diseños experimentales o cuasi-experimentales).
SEM y Causalidad: Una Advertencia Crucial
2. Verificación de Teorías:
- La lógica es: “Si mi teoría es una buena representación de la realidad, entonces la estructura de covarianzas que mi teoría implica debería ser muy similar a la estructura de covarianzas que observo en mis datos”.
- SEM nos proporciona una herramienta poderosa para realizar esta comprobación de forma rigurosa.
Estructura de un Modelo SEM: Un Modelo de “Dos Partes”
Un modelo SEM completo se puede entender como la unión de dos sub-modelos que se estiman simultáneamente:
1. Modelo de Medida:
- Propósito: Define cómo cada constructo latente se mide a través de sus indicadores observables.
- Equivalencia: Es, en esencia, un Análisis Factorial Confirmatorio (AFC). Especifica qué ítems cargan en qué factores, permitiendo evaluar la validez y fiabilidad de nuestras mediciones al modelar explícitamente el error de cada indicador.
Estructura de un Modelo SEM: Un Modelo de “Dos Partes”
2. Modelo Estructural:
- Propósito: Define las relaciones causales (paths) hipotetizadas entre los constructos (generalmente, entre las variables latentes).
- Equivalencia: Es, en esencia, un Análisis de Senderos (Path Analysis). Permite testear hipótesis sobre efectos directos e indirectos.
Casos Especiales de SEM que ya conocemos
- Análisis Factorial Confirmatorio (AFC): Es un SEM que solo contiene el modelo de medida. Se enfoca en la calidad de la medición y las relaciones entre los factores son solo correlacionales, no direccionales.
- Análisis de Senderos (Path Analysis): Es un SEM que no contiene variables latentes; las variables observadas se tratan como si fueran mediciones perfectas de los conceptos (se equiparan las variables observadas con las latentes). Por lo tanto, solo existe el modelo estructural y los errores de medición se confunden con los errores de predicción en un único término de error para cada variable endógena.
Tipos de Variables en un Modelo Estructural
- Variable Observada o Indicador: Se mide directamente en los datos (ej. preguntas de un cuestionario).
- Variable Latente (o Factor): Constructo teórico que no se observa directamente y que el modelo asume está libre de error de medición. Se infiere a partir de sus indicadores.
- Variable de Error: Representa la varianza no explicada. Hay dos tipos:
- Error de Medición: Asociado a cada indicador, es la varianza de ese indicador que no es explicada por su factor latente.
- Error Estructural (o Perturbación): Asociado a cada variable endógena (latente u observada), es la varianza de esa variable que no es explicada por sus predictores en el modelo.
- Variable Exógena: Sus causas están fuera del modelo. No recibe flechas direccionales de ninguna otra variable en el modelo.
- Variable Endógena: Recibe al menos una flecha direccional. Su variación es (parcialmente) explicada por el modelo.
Diagramas Estructurales: Convenciones
1. Representación de Variables:
- Rectángulos: Variables Observables (Indicadores).
- Óvalos o Círculos: Variables No Observables (Latentes, Errores).
2. Representación de Relaciones:
- Flechas Rectas Unidireccionales (\(\longrightarrow\)): Efectos estructurales directos (regresión).
- Flechas Curvas Bidireccionales (\(\longleftrightarrow\)): Correlaciones o covarianzas no analizadas (generalmente entre variables exógenas o entre términos de error).
- Parámetros: Los coeficientes (cargas, paths) se pueden mostrar sobre las flechas.
3. Término de Error:
- Cada variable endógena (latente u observada) debe tener un término de error asociado, representado por una flecha que apunta hacia ella.
Ejemplo de un Modelo SEM Completo
Teoría del Modelo:
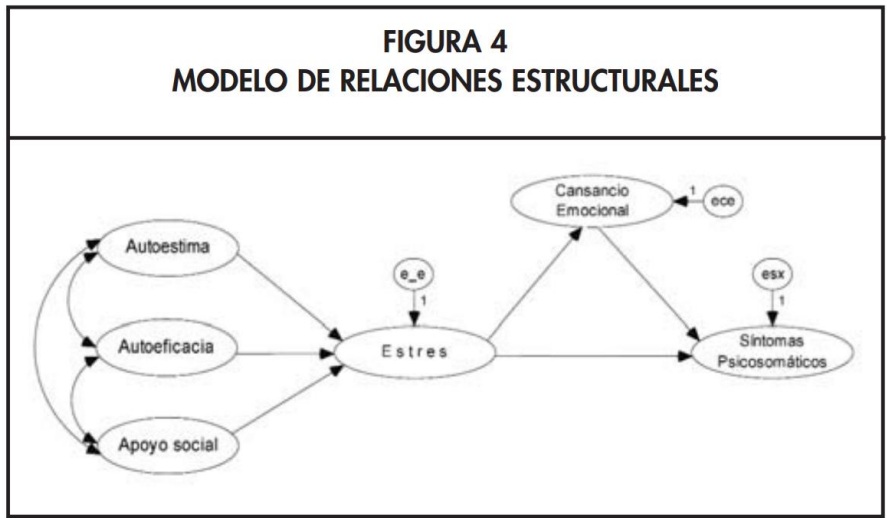
- Constructos Latentes: Autoestima, Autoeficacia, Apoyo Social (exógenos); Estrés, Cansancio Emocional, Síntomas Psicosomáticos (endógenos).
- Modelo Estructural (Fig. 4): Hipotetiza las relaciones causales entre los constructos.
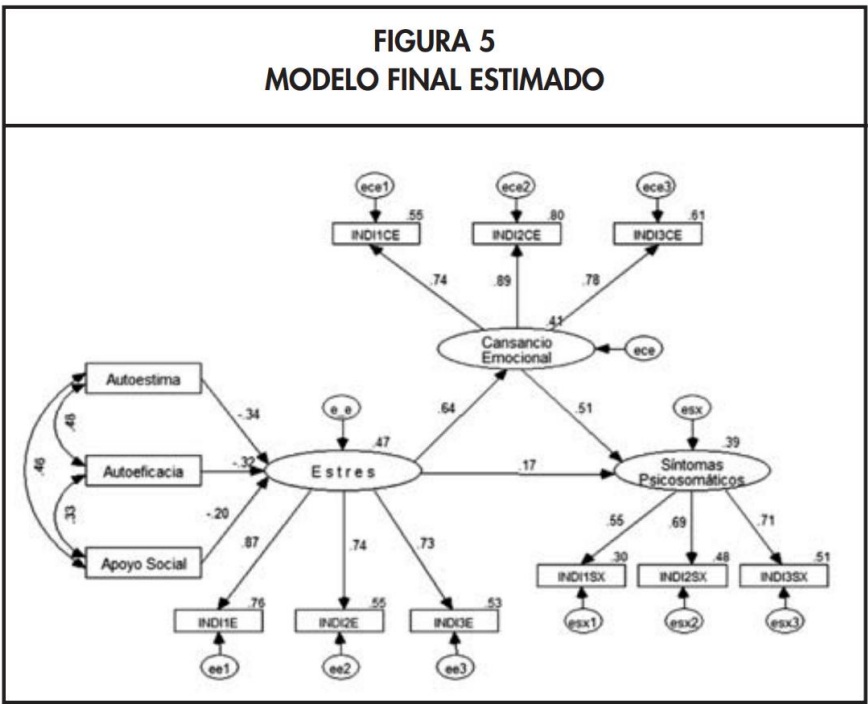
- Modelo de Medida (Fig. 5): Cada constructo se mide a través de tres indicadores observables (ej.
INDI1CE, INDI2CE, INDI3CE para Cansancio Emocional).
- Modelo Final (Fig. 5): Integra ambas partes, permitiendo analizar las relaciones entre los constructos mientras se controla el error de medición.
Figura 4: Modelo Estructural ![]()
Ejemplo de un Modelo SEM Completo
![]()
Figura 5: Modelo Final Estimado (con modelo de medida)
Tipos de Relaciones en SEM
Los SEM nos permiten explorar una rica variedad de relaciones entre variables:
- Covariación vs Causalidad: Distinguir entre mera asociación y relaciones direccionales hipotetizadas.
- Relación Espuria: Identificar cuando la correlación entre dos variables se debe a una causa común.
- Relación “Causal” Directa e Indirecta: Descomponer el efecto total, identificando mecanismos de mediación.
- Relación “Causal” Recíproca: Modelar bucles de retroalimentación (feedback loops).
- Efectos Totales: La suma de los efectos directos e indirectos.
Supuestos de los Modelos de Ecuaciones Estructurales
- Tamaño de muestra suficientemente grande: Mínimo 200, pero idealmente 10-20 casos por parámetro a estimar.
- Relaciones lineales entre las variables.
- Normalidad multivariante (importante para el método de estimación ML).
- Identificación del modelo (grados de libertad > 0).
- Ausencia de multicolinealidad entre predictores.
- Variables continuas (o uso de estimadores apropiados para categóricas como DWLS).
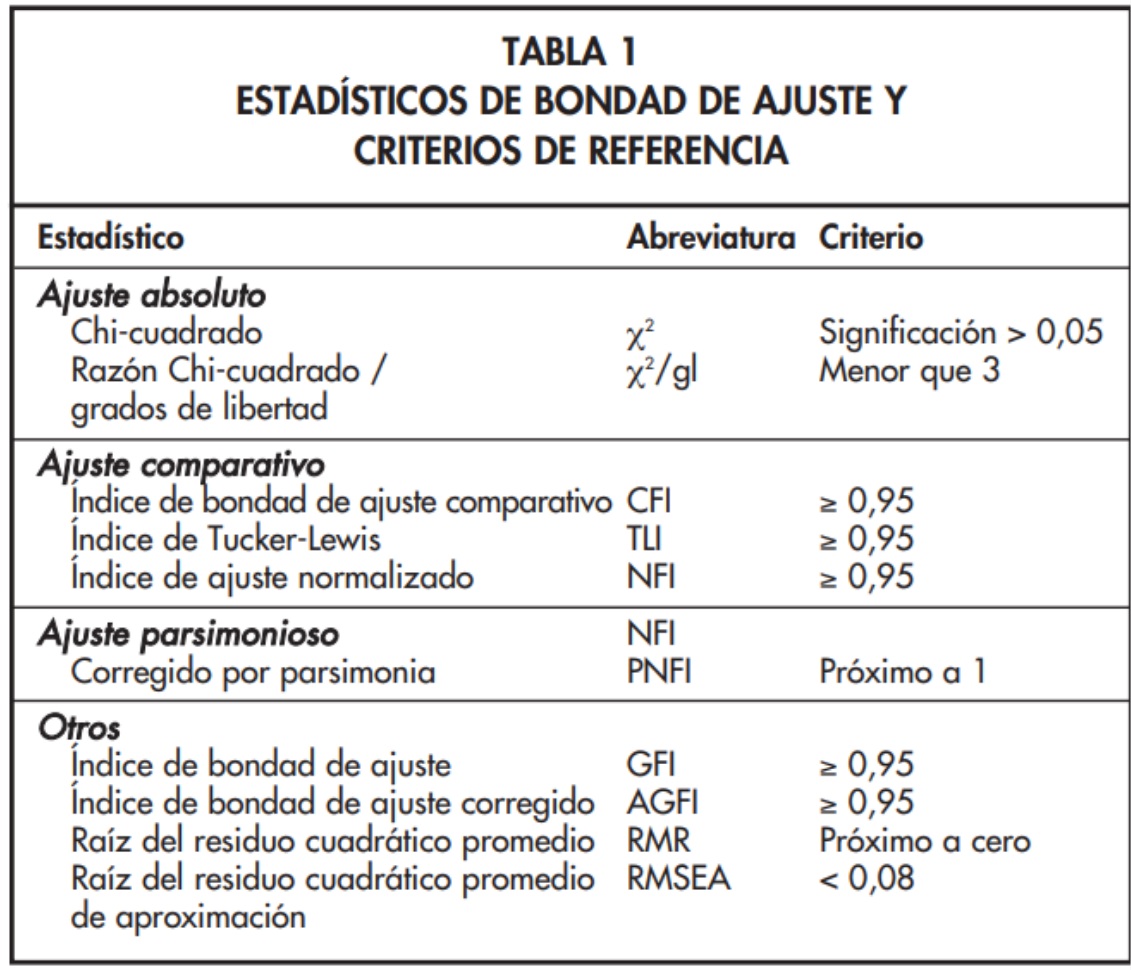 (Tabla de referencia con criterios comunes)
(Tabla de referencia con criterios comunes)